The χ2 statistic
As an example we consider here the relationship between left right
self-placement and support for Switzerland being a member of the European Union.
 If we consider the marginal frequency of this table,
it appears that 58% of the sample is in favour of EU membership.
If left-right
self-placement were totally independent from support for European integration,
one would expect 58% of the leftists, 58% of centrists and again 58% of the
right-wingers to be in favour of Switzerland's membership of European Union.
This is obviously not the case, but as we are working with random samples
we must first assume that the actual difference between, for example left and centre
of 15.7%, is just random, i.e. due to sample fluctuations.
Before interpreting the differences and the relationship we are
assuming that the variables are and
have to ask first, whether the relationship is
.
If we consider the marginal frequency of this table,
it appears that 58% of the sample is in favour of EU membership.
If left-right
self-placement were totally independent from support for European integration,
one would expect 58% of the leftists, 58% of centrists and again 58% of the
right-wingers to be in favour of Switzerland's membership of European Union.
This is obviously not the case, but as we are working with random samples
we must first assume that the actual difference between, for example left and centre
of 15.7%, is just random, i.e. due to sample fluctuations.
Before interpreting the differences and the relationship we are
assuming that the variables are and
have to ask first, whether the relationship is
.
 Let us work out this assumption of independence (the independence model).
Very precisely, the probability to be in favour of EU integration is 57.98%
(414/714), the probability to be left is 24.09% (172/714). So if the two
variables were totally independent we would expect roughly 100 leftists to
be in favour of European Union membership =(0.5798*0.2409*714).
This frequency is
called the .
As we can see, the
in this cell is 130 (the
leftists in favour of EU membership in our sample). This means that we have
roughly 30 more than expected.
This value is the difference between the observed and expected frequency
(difference from independence).
Let us work out this assumption of independence (the independence model).
Very precisely, the probability to be in favour of EU integration is 57.98%
(414/714), the probability to be left is 24.09% (172/714). So if the two
variables were totally independent we would expect roughly 100 leftists to
be in favour of European Union membership =(0.5798*0.2409*714).
This frequency is
called the .
As we can see, the
in this cell is 130 (the
leftists in favour of EU membership in our sample). This means that we have
roughly 30 more than expected.
This value is the difference between the observed and expected frequency
(difference from independence).
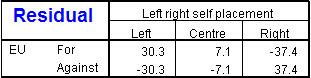 These differences (also called "residuals") from the independence
table (table of expected frequencies) are the basis of the statistic.
These differences (also called "residuals") from the independence
table (table of expected frequencies) are the basis of the statistic.
Crosstabs lets you produce tables containing
observed, expected and residual (unstandardized) frequencies. (Select from
the Cells dialog or use syntax.
CROSSTABS /TABLES=q28r BY d01r
/CELLS= COUNT EXPECTED RESID .
The χ2 statistic is based on the difference between
the expected and the observed number of cases and it permits to test the
hypothesis that row and column variables are independent.
It is calculated
by summing over all cells the squared residuals divided by the expected
frequency.
In our case the χ2 value, as we can see under "Pearson chi-square"
in the output, is:
54.28 = (30.3)2/99.7 + (7.1)2/209.9 +
(-37.4)2/104.4+
(-30.3)2/72.3 +
(-7.1)2/152.1 +
(37.4)2/75.6
The χ2 test
Generally a statistical test works as follows:
Your research hypothesis is that there is a relationship between
self-placement on the left-right scale (3 categories) and EU membership;
when looking at our table we want to know
whether we can interpret the relationship we see in the table (based on
a random ), as a relationship among all Swiss citizens
(), i.e. in other
words can we from the sample that
there is a "true" relationship in the population.
()
- Formulate a
that the two variables are
and a that the variables
are dependent.
More precisely statistical testing is about finding out whether we
can reject the [H0]
(and therefore
accept the [H1] or if we
have to keep H0.
- Specify significance level (α) that defines a threshold, indicating what
risk you are prepared to take when deciding. In statistics certainty does
not exist, we will never be sure, there is always
a probability that the
be true, but we want that probability to be low, how low is indicated by that level.
Typical levels considered
are 0.05 (or 5%), 0.01 (or 1%), 0.001 (1‰).
Never forget that choosing a level is your personal decision stating the risk you
are prepared to take that H0 is true when you decide to reject it.
To make it very clear: In a medical experiment with a possible lethal issue for
your patients, would you accept an α level of 0.05 that it implies a risk
of 5 patients out of 100 dying because of your experiment?
- Compute a test statistic (χ2 statistic)from the table
and compare it to the theoretical χ2 distribution.
- If the probability that the relationship could have been produced
by chance (this is same as saying the
is true) is below the threshold we
have set (),
we reject the : this implies
accepting the
in order words we can say the variables are dependent (related).
To perform the χ2 test,
we will have to compare the calculated χ2 statistic
to the critical points of the theoretical χ2 distribution.
To do that SPSS computes the probability that the observed χ2 could have
been produced by chance (just random fluctuation).
More specifically, on the SPSS output you will find under
Asymp. Sig. (2-sided) a value of 0.000.
As this value (probability), often called the ,
is lower than the (threshold)
you have specified, let's say 0.01, we can reject the
.
Additional remarks
The Pearson χ2and the others...
Above we have explained the classical χ2 statistic, also called
the Pearson χ2. There are other, for example
the
("Likelihood ratio" in the output) is an alternative to the
. It is based on maximum-likelihood
theory. For large samples it is identical to Pearson χ2. It is recommended
especially for small samples.
Sample size
The magnitude of the χ2 statistics depends not only on goodness
of fit, but also on the sample size. If the sample
size is multiplied by n, so does the χ2 statistic.
This means
that for large sample sizes, nearly every relationship is statistically significant,
small samples nearly never are.
For these reasons, one must be very cautious about the
interpretation, as statistical significance is related to sample size.
Some additional rules
The expected frequencies for each category should be at
least 1.
No more than 20% of the categories should have expected frequencies
of less than 5. This can happen for small samples or crosstabulations with
many cells. SPSS supplies this information in a note
at the bottom of the
"Chi-Square Tests" table.
Degrees of freedom
On the table you will also fined a column labelled "df".
This corresponds to
the .
As the chi-square test depends also
on the number
of rows and columns of the table.
For a r x c table it is
(r-1) x (c-1). Our table here, as you can see in the
output has 2 degrees
of freedom ("df" on the same line) which is simply
(2-1) x (3-1).
The degrees of freedom can be viewed as the number
of cells that need to be set, until all others are fixed, given the constraints
of the marginal frequencies.
Note as SPSS supplies the actual p-value, there is no need to look up
the chi-square statistic's value in a statistical table printed in a book
and find there the critical value corresponding to both the
and the
.