how the brain distinguishes between voice and sound
Researchers at UNIGE and at Maastricht University have demonstrated that the brain adapts to a person’s listening intentions by focusing either on a speaker’s voice or on the speech sounds that are being uttered.
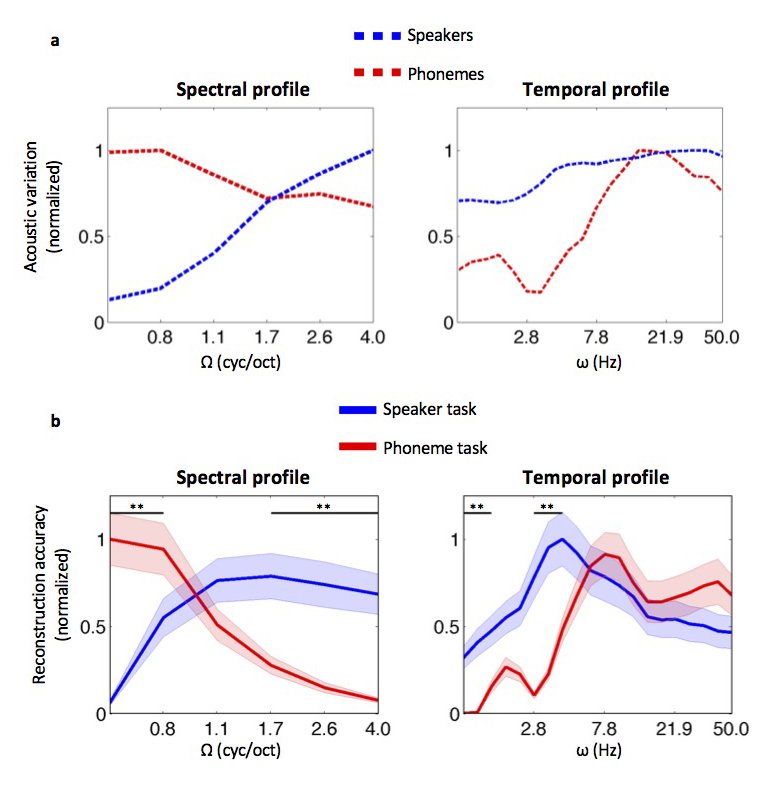
On top: Analysis of main acoustic parameters underlying differences in the voices (speakers) and in the speech sounds (phonemes) in the pseudo-words themselves: high spectral modulations best differentiate the voices (blue spectral profile), and fast temporal modulations (red temporal profile) along with low spectral modulations (red spectral profile) best differentiate the speech sounds. At the bottom: Analysis of neural, fMRI data: during performance of the voice task, the auditory cortex amplifies higher spectral modulations (blue spectral profile), and during performance of the phoneme task, it amplifies fast temporal modulations (red temporal profile) and low spectral modulations (red spectral profile). These amplification profiles are highly similar to the acoustic profiles to differentiate between the voices and the phonemes. © UNIGE
Is the brain capable of distinguishing a voice from the specific sounds it utters? In an attempt to answer this question, researchers from the University of Geneva (UNIGE), Switzerland, – in collaboration with the University of Maastricht, the Netherlands – devised pseudo-words (words without meaning) spoken by three voices with different pitches. Their aim? To observe how the brain processes this information when it focuses either on the voice or on speech sounds (i.e. phonemes). The scientists discovered that the auditory cortex amplifies different aspects of the sounds, depending on what task is being performed. Voice-specific information is prioritised for voice differentiation, while phoneme-specific information is important for the differentiation of speech sounds. The results, which are published in the journal Nature Human Behaviour, shed light on the cerebral mechanisms involved in speech processing.
Speech has two distinguishing characteristics: the voice of the speaker and the linguistic content itself, including speech sounds. Does the brain process these two types of information in the same way? “We created 120 pseudo-words that comply with the phonology of the French language but that make no sense, to make sure that semantic processing would not interfere with the pure perception of the phonemes,” explains Narly Golestani, professor in the Psychology Section at UNIGE’s Faculty of Psychology and Educational Sciences (FPSE). These pseudo-words all contained phonemes such as /p/, /t/ or /k/, as in /preperibion/, /gabratade/ and /ecalimacre/.
The UNIGE team recorded the voice of a female phonetician articulating the pseudo-words, which they then converted into different, lower to higher pitched voices. “To make the differentiation of the voices as difficult as the differentiation of the speech sounds, we created the percept of three different voices from the recorded stimuli, rather than recording three actual different people,” continues Sanne Rutten, researcher at the Psychology Section of the FPSE of the UNIGE.
How the brain distinguishes different aspects of speech
The scientists scanned their participants using functional magnetic resonance imaging (fMRI) at high magnetic field (7 Tesla). This method allows to observe brain activity by measuring the blood oxygenation in the brain: the more oxygen is needed, the more that particular area of the brain is used. While being scanned, the participants listened to the pseudo-words: in one session they had to identify the phonemes /p/,/t/ or /k/, and in another they had to say whether the pseudo-words had been read by voice 1, 2 or 3.
The teams from Geneva and the Netherlands first analysed the pseudo-words to better understand the main acoustic parameters underlying the differences in the voices versus the speech sounds. They examined differences in frequency (high / low), temporal modulation (how quickly the sounds change over time) and spectral modulation (how the energy is spread across different frequencies). They found that high spectral modulations best differentiated the voices, and that fast temporal modulations along with low spectral modulations best differentiated the phonemes.
The researchers subsequently used computational modelling to analyse the fMRI responses, namely the brain activation in the auditory cortex when processing the sounds during the two tasks. When the participants had to focus on the voices, the auditory cortex amplified the higher spectral modulations. For the phonemes, the cortex responded more to the fast temporal modulations and to the low spectral modulations. “The results show large similarities between the task information in the sounds themselves and the neural, fMRI data,” says Golestani.
This study shows that the auditory cortex adapts to a specific listening mode. It amplifies the acoustic aspects of the sounds that are critical for the current goal. “This is the first time that it’s been shown, in humans and using non-invasive methods, that the brain adapts to the task at hand in a manner that’s consistent with the acoustic information that is attended to in speech sounds,” points out Rutten. The study advances our understanding of the mechanisms underlying speech and speech sound processing by the brain. “This will be useful in our future research, especially on processing other levels of language – including semantics, syntax and prosody, topics that we plan to explore in the context of a National Centre of Competence in Research on the origin and future of language that we have applied for in collaboration with researchers throughout Switzerland,” concludes Golestani.