Gallic(orpor)a - extraction, annotation et diffusion de l'information textuelle et visuelle en diachronie longue
Projet
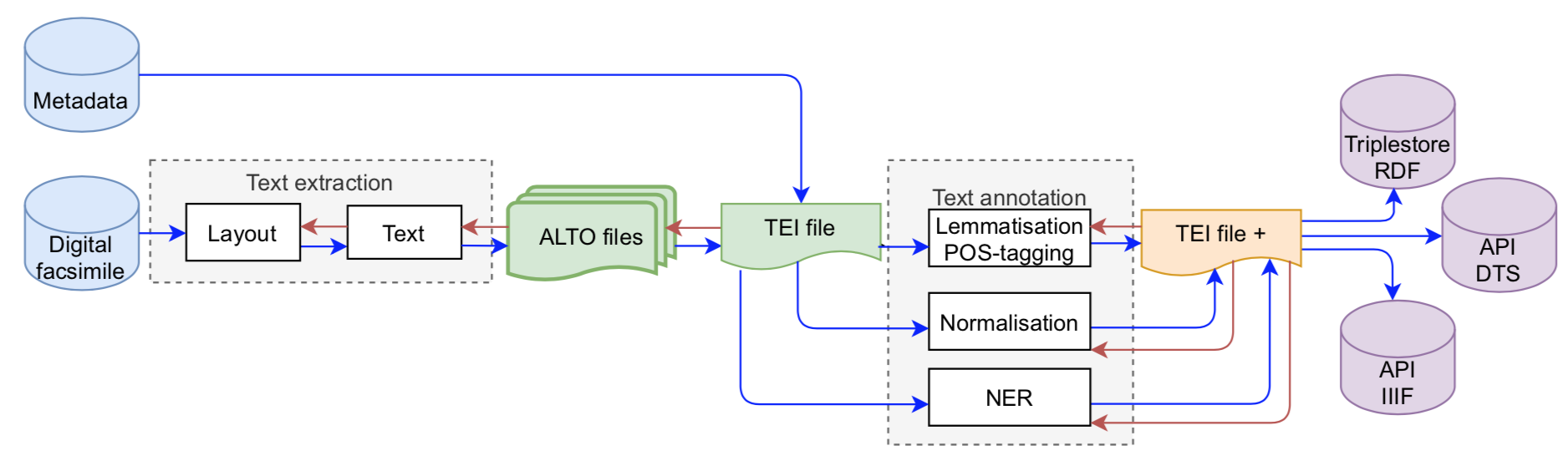
Notre projet propose de consolider et d'appliquer une chaîne de traitement pour les documents anciens de Gallica en diachronie longue, des premiers manuscrits français aux imprimés révolutionnaires. Au delà de la simple extraction de texte en masse, nous améliorerons les jeux de données d'entraînement pour l'apprentissage machine, les outils et les modèles déjà existants pour l'extraction, l'annotation et la diffusion de données richement annotées provenant des collections de la Bibliothèque nationale de France (BnF).
Publications
- Ariane Pinche, Kelly Christensen, Simon Gabay. Between automatic and manual encoding: Towards a generic TEI model for historical prints and manuscripts. TEI 2022 conference : Text as data, Sep 2022, Newcastle, United Kingdom. ⟨10.5281/zenodo.7092214⟩. ⟨hal-03780302⟩
- Simon Gabay, Ariane Pinche, Kelly Christensen. Gallic(orpor)a : Processing Gallica's historical sources. UNIGE Data Science Day, Sep 2022, Genève, Switzerland. ⟨hal-03819326⟩